参考慕课网并发课程做的笔记
当多个线程访问某个类时候,不管运行时环境采取任何调度方式或者这些进程如何交替执行,并且在主调代码中不需要任何额外的同步或者协同,这个类都能变现出正确行为,那么称这个类就是线程安全的
- 原子性:提供了互斥访问,同一时刻只能有一个线程来对他进行操作。
- 可见性:一个线程对主内存的修改可以及时的被其他线程观察到。
- 有序性:一个线程观察其他线程中的指令执行顺序,由于指令重 拍顺序的存在,该观察结果一般杂乱无章。
原子性-Atomic包
在java.util.concurrent.atomic并且unsafe类提供了硬件级别的原子操作
AtomicInteger.getAndIncrement的源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/**
* 获取底层当前的值并且+1
* @param var1 需要操作的AtomicInteger 对象
* @param var2 当前的值
* @param var4 要增加的值
*/
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
// 获取底层的该对象当前的值
var5 = this.getIntVolatile(var1, var2);
//获取完底层的值和自增操作之间,可能系统的值已经又被其他线程改变了
//如果底层的值var5 等于var2则做var5+var4的操作
//如果又被改变了,则重新计算系统底层的值,并重新执行本地方法
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
- AtomicLong、LongAdder(JDK1.8+)
我们看到AtomicLong在执行CAS操作的时候,是用死循环的方式,如果竞争非常激烈,那么失败量就会很高,性能会受到影响。所以AtomicLong适合低并发
再看一下1.8以后的LongAdder
1
2
3
4
5
6
7
8
9
10
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
jvm对long,double这些64位的变量拆成两个32位的操作
LongAdder的设计思想:核心是将热点数据分离,将内部数据value分成一个数组,每个线程访问时,通过hash等算法映射到其中一个数字进行技术,而最终计数结果为这个数组的求和累加,其中热点数据value会被分离成多个热点单元的数据cell,每个cell独自维护内部的值,当前value的实际值由所有的cell累积合成,从而使热点进行了有效的分离,提高了并行度。
- 优点:LongAdder 在低并发的时候通过直接操作base,可以很好的保证和Atomic的性能基本一致,在高并发的场景,通过热点分区(将单点的跟新压力分散到个各个节点上)来提高并行度。
- 缺点:在统计的时候如果有并发更新,可能会导致结果有些误差,所以需要准确的数值,例如序列号生成还是AtomicLong是好的选择。
- AtomicReference、AtomicReferenceFieldUpdater (不是特别重点)
AtomicReference: 用法同AtomicInteger一样,但是可以放各种对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@ThreadSafe
@Slf4j
public class AtomicExample4 {
private static AtomicReference<Integer> count = new AtomicReference(0);
public static void main(String[] args) {
count.compareAndSet(0, 2);
count.compareAndSet(0, 1);
count.compareAndSet(1, 3);
count.compareAndSet(2, 4);
count.compareAndSet(3, 5);
log.info("count {}", count.get());
}
}
- AtomicReferenceFieldUpdater
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
@ThreadSafe
@Slf4j
public class AtomicExample5 {
/**
* AtomicIntegerFieldUpdater 核心是原子性的去更新某一个类的实例的指定的某一个字段
* 构造函数第一个参数为类定义,第二个参数为指定字段的属性名,必须是volatile修饰并且非static的字段
*/
private static AtomicIntegerFieldUpdater<AtomicExample5> updater =
AtomicIntegerFieldUpdater.newUpdater(AtomicExample5.class, "count");
@Getter
public volatile int count = 100;
public static void main(String[] args) {
AtomicExample5 example5 = new AtomicExample5();
if (updater.compareAndSet(example5, 100, 120)) {
log.info("update success1 {}", example5.getCount());
}
if (updater.compareAndSet(example5, 100, 120)) {
log.info("update success2 {}", example5.getCount());
} else {
log.info("update failed {}", example5.getCount());
}
// 1.success 1 2.failed
}
}
- AtomicStampReference:
ABA问题:在CAS操作的时候,其他线程将变量的值A改成了B由改成了A,本线程使用期望值A与当前变量进行比较的时候,发现A变量没有变,于是CAS就将A值进行了交换操作,这个时候实际上A值已经被其他线程改变过,这与设计思想是不符合的
解决思路:每次变量更新的时候,把变量的版本号加一,这样只要变量被某一个线程修改过,该变量版本号就会发生递增操作,从而解决了ABA变化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
/**
* Atomically sets the value of both the reference and stamp
* to the given update values if the
* current reference is {@code ==} to the expected reference
* and the current stamp is equal to the expected stamp.
*
* @param expectedReference the expected value of the reference
* @param newReference the new value for the reference
* @param expectedStamp the expected value of the stamp(上面提到的版本号)
* @param newStamp the new value for the stamp
* @return {@code true} if successful
*/
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
-
AtomicLongArray 可以指定更新一个数组指定索引位置的值.具体见源码
-
AtomicBoolean(平时用的比较多) compareAndSet方法也值得注意,可以达到同一时间只有一个线程执行这段代码
原子性-锁
- synchronized:依赖JVM (主要依赖JVM实现锁,因此在这个关键字作用对象的作用范围内,都是同一时刻只能有一个线程进行操作的)
- Lock:依赖特殊的CPU指令,代码实现,ReentrantLock
synchronized:当两个并发线程(thread1和thread2)访问同一个对象(syncThread)中的synchronized代码块时,在同一时刻只能有一个线程得到执行,另一个线程受阻塞,必须等待当前线程执行完这个代码块以后才能执行该代码块。Thread1和thread2是互斥的,因为在执行synchronized代码块时会锁定当前的对象,只有执行完该代码块才能释放该对象锁,下一个线程才能执行并锁定该对象。但是也要这主意每个对象只有一个锁(lock)如果声明多个对象则每个对象互不干扰
原子性-对比
- synchronize:不可中断,适合竞争不激烈,可读性好。
- lock:可中断锁,多样化同步,竞争激烈时能维持常态。
- atomic:竞争激烈时能维持常态,比lock性能好,但只能同步一个值。
可见性
一个线程对主线程的修改可以及时的被其他线程观察到
导致共享变量在线程中不可见的原因:
- 线程交叉执行。
- 重排序结合线程交叉执行。
- 共享变量更新后的值没有在工作内存与主内存间及时更新。
java提供了synchronized和volatile 两种方法来确保可见性
JMM(java内存模型)关于synchronized的两条规定:
- 线程解锁前,必须把共享变量的最新值刷新到主内存。
- 线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新读取最新的值(注意,加锁和解锁是同一把锁)。
. volatile:通过加入内存屏障和禁止重排序优化来实现

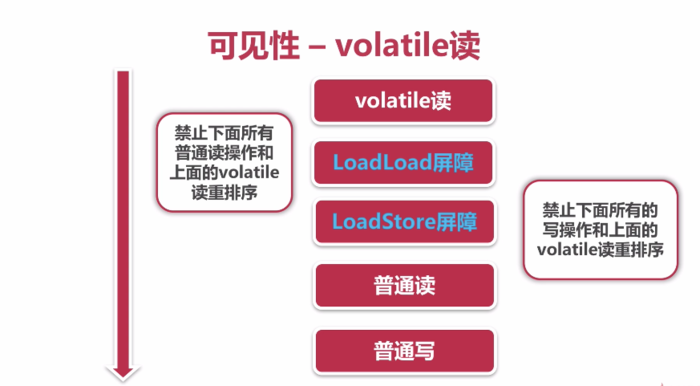
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
@Slf4j
@NotThreadSafe
public class CountExample4 extends AbstractExample{
/** 请求总数 */
public static int clientTotal = 5000;
/** 同时并发执行的线程数 */
public static int threadTotal = 50;
public volatile static int count = 0;
/**
* 本质上应该是这个方法线程不安全
*
* volatile只能保证 1,2,3的顺序不会被重排序
* 但是不保证1,2,3的原子执行,也就是说还是有可能有两个线程交叉执行1,导致结果不一致
*/
@Override
protected void add() {
// 1.取内存中的count值
// 2.count值加1
// 3.重新写会主存
count++;
}
@Override
protected void countLog() {
log.info("count:{}",count);
}
public static void main(String[] args) throws InterruptedException {
new CountExample4().add();
}
}
volatile使用条件
- 对变量写操作不依赖于当前值
- 该变量没有包含在具有其他变量的不必要的式子中
综上,volatile特别适合用来做线程标记量,如下图

有序性
java 内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程的并发执行的正确性
- happens-before原则
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作。
- 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作。
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作。
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C 则可以得出操作A先行发生于操作C
- 线程启动原则:Thread对象的start方法先行发生于此线程的每一个动作
- 线程中断规则:对线程interrupt方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 线程终结规则:线程中所有操作都先行发生于线程的终止检测,可以通过Thread.join方法结束,Thread.isAlive的返回值检测到线程已经终止执行。
- 对象终结规则:一个对象的初始化完成先行发生于它的finalize方法的开始
第一条规则要注意理解,这里只是程序的运行结果看起来像是顺序执行,虽然结果是一样的,jvm会对没有变量值依赖的操作进行重排序,这个规则只能保证单线程下执行的有序性,不能保证多线程下的有序性
Happens-before原则,先天有序性,即不需要任何额外的代码控制即可保证有序性,如果两个操作的次序不能从这八种规则中推倒出来,则不能保证有序性。