什么是拥塞
当网络变得拥塞时,路由器因无法处理高速率到达的流量而被迫丢弃数据信息的现象称为拥塞
与流量控制的区别
理论原理相似,都是通过窗口管理进行控制,流量控制主要是依赖于连接的发送端和接收端 (4层以上),拥塞控制主要基于路由器(4层以下)
拥塞控制的主要方法
慢启动、拥塞避免、快速恢复
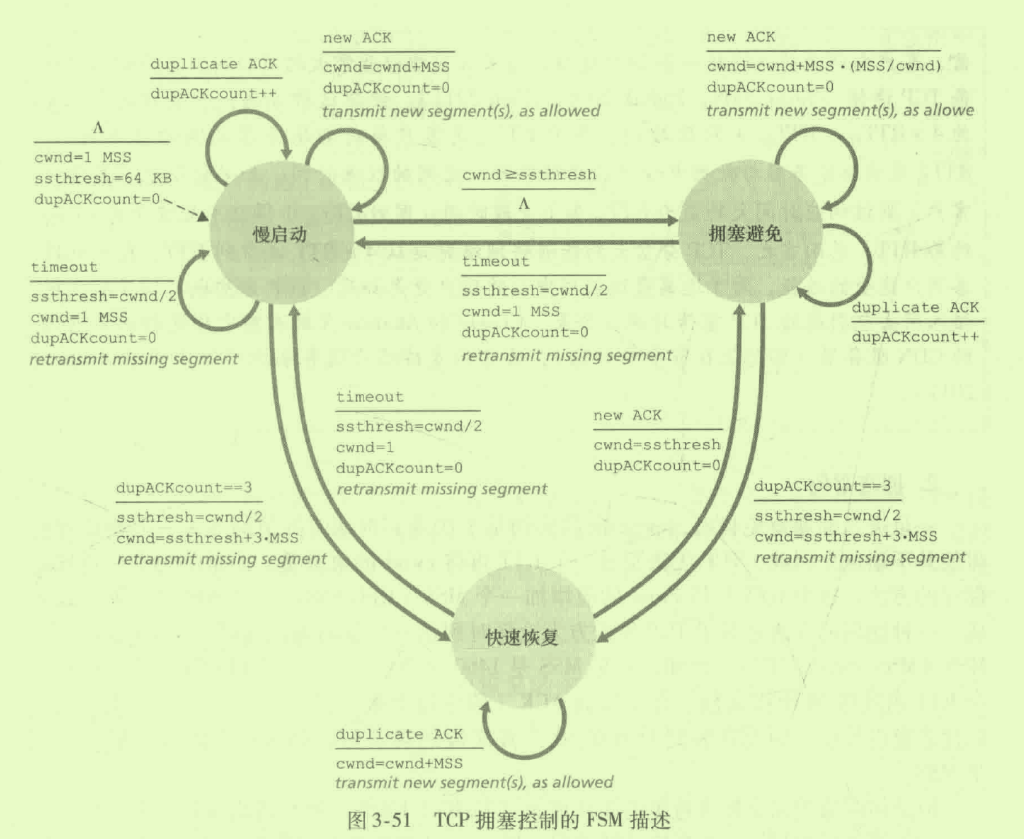 图:《计算机网络 自顶向下方法(第七版)》
图:《计算机网络 自顶向下方法(第七版)》
慢启动
一条TCP连接开始,通常不会立刻处于最高速率,是根据相关算法一点点将速率提升上去的。
慢启动算法
慢启动算法如下: cwnd = MSS 收到一个ACK 线性增长 cwnd++; RTT阶段指数增长 cwnd * 2
拥塞避免
拥塞避免算法
拥塞避免算法如下:
每个RTT中 只累计增加1个MSS。
一共N个包,收到一个ACK,cwnd = cwnd + 1 / ( N * MSS )
每当过一个RTT,cwnd = cwnd+1
TCP中是使用慢启动还是拥塞避免算法完全是取决于cwnd和ssthresh这两个值。从上面的图也能看出来。当cwnd < ssthresh 是使用慢启动 ,否则就是使用拥塞避免。
如果在慢启动和拥塞避免中出现RTO情况下:
- sshthresh = cwnd / 2 .
- cwnd = MMS
- 进入/重新进入
慢启动过程
至此慢启动和拥塞避免算法组成了TCP拥塞控制算法的第一部分。
Tahoe,Reno,快速恢复算法
早期的Tahoe TCP版本比较粗糙,在连接之初就是出于慢启动阶段,一旦检测到丢包无论是RTO还是快速重传,都会按照上面的RTO情况进行处理。
由于Tahoe 会带来带宽利用率低下,从而进一步进行版本优化。出现了Reno TCP。针对不同类型的丢包使用不同的处理方式。 RTO引发的丢包处理方式不变。 三个冗余ACK的丢包情况下:
- cwnd = cwnd / 2
- ssthresh = cwnd
- 进入
快速恢复算法
快速恢复算法
- 启动款速重传,cwnd的值都增加一个MSS,cwnd = cwnd + 3 * MSS
- 再收到 重复ACK ,cwnd = cwnd +MSS
- 如果收到新的ACK cwnd = ssthresh 并且进入
拥塞模式
TCP Reno 算法得到了广泛的应用,并且称为”标准TCP“的基础,后面基于它又有更多跟新优化。
NewReno算法
解决了什么问题
NewReno主要针对快速恢复算法进行优化,Reno算法中依赖三次返回的重复ACK。这导致有个问题存在,可能有多个包丢失,但是返回的ACKS并不能代表所有的数据包。Reno只重传一个,剩下的包只能等RTO,这就会出现多个超时会使当前TCP传输速度急速下降。
NewReno算法
NewReno 算法(1995年)是在没有SACK(1996年)支持下改进快速恢复算法。
在接受到三个重复ACKS进入快速恢复模式,同时会近路上个传输数据窗口的最高序列号,只有当收到的序列号不小于恢复点的ACK,才会停止快速恢复阶段。 当成功接受一个ACK后可能继续发送一个新的数据段,这样做也是为了减少重传超时,
采用SACK机制的NewReno算法
采用SACK机制后,发送方通常只发送丢失的数据,直到完成所有重传。
快速重传TCP和选择重传TCP的区别
快速重传情况下,如果出现丢包,TCP发送方会一个一个重传已经丢失的数据包【具体见2.TCP超时与重传】 采用SACK级之后,发送后知晓多个数据段丢失的情况,可以立刻重传,不过该模式下会可能会短时间发送大量数据,使本来拥塞的网络更雪上加霜了。
FACK算法
TCP SACK 版本的进一步优化。
- 用个变量FAC记录最大序列号,如果网络正常,FACK = SND.UNA 【具体见3.流量控制】发送方的窗口模型)
- 统计在外传输数据 (awnd),正常情况下awnd = SND.NXT - FACK
- 如果需要从新传输数据 awnd = SND.NXT - FACK + retran_data ,就是说awnd是传出的数据+重传的数据。
- 当SACKZ中最大一个数据和ACK比较长了就触发重传,直到SND.NXT<=SND.UNA ,所有重传数据都被确认了,进入拥塞避免。
后记
随着时间推移,关于拥塞控制的相关优化算法很多的,后续再慢慢补充吧。每次进行资料阅读都会有新的理解,所以关于TCP/IP相关博客文肯定会有新增和修改。
由于英语能力有限,RFC没有阅读过,只是通过书和其他博客进行学习记录。实在有所不甘,只希望能快点读的懂RFC
资料引用
- TCP 的那些事儿(下)
- 《TCP/IP 详解卷1》
- 《计算机网络 自顶向下方法(第七版)》